#3 Smart Text Extraction in Businesses with Pega
.svg)


By creating entity extraction models to identify keywords and phrases, cases can be automatically created, forms filled out, or orders forwarded. Each entity extraction model classifies keywords and phrases—such as people’s names, places, organizations, and so on—into predefined categories known as entity types.
To identify each entity type in unstructured text, various recognition methods are combined. Entity types can be used to create and manage complex models for entity extraction, such as for dates or dates and times. In addition, entity types support the management of nested entities. For example, an address may contain nested entity types such as country, state, province, ZIP code, street, etc.
In addition to the keyword-based method and the machine learning method, RUTA scripts can also be used here to identify entities. The Apache UIMA RUTA script is a rule-based scripting language used to recognize patterns in text. Annotations are used in conjunction with conditions to define the patterns. As soon as a pattern matches, the corresponding action is executed. Additionally, regular expressions can be used in the script to find the patterns.
For text extraction, only the Conditional Random Fields (CRF) algorithm is available, unlike in the topic model. The choice between keyword lists and machine learning, as well as entity recognition using RUTA scripts, are available options. Unlike topic detection, all entities are stored in a list, and the F-score provides information about the model’s performance.
Conditional Random Fields (CRF)
CRFs are an important type of machine learning model, particularly in natural language processing. They are used for text segmentation, tagging, and the recognition of named entities such as people and organizations. Compared to simpler models like hidden Markov models, CRFs can account for a wider range of features and contexts. The algorithm is defined by the conditional probability P(y│x) using feature functions that model dependencies between input and output variables. CRFs are supervised learning models and can be adapted to specific requirements.
Feature Functions
CRFs use feature functions to model dependencies between input and output variables. These functions utilize contextual information to make accurate predictions and enable the integration of domain-specific knowledge. Feature functions are crucial for the scalability and efficiency of the CRF model. They serve to capture relevant contextual information and incorporate it into the modeling process to achieve a better representation of the data.
Example of a feature function
A feature function f(x,i,y_i,y_(i-1)) can take on a value of either 1 or 0 based on a specific condition. This allows for the integration of various questions and increases the effectiveness and accuracy of the analysis and predictions.
The flexibility of CRFs in model design, their adaptability to specific requirements, and their ability to account for contextual information make them a powerful tool in text extraction.
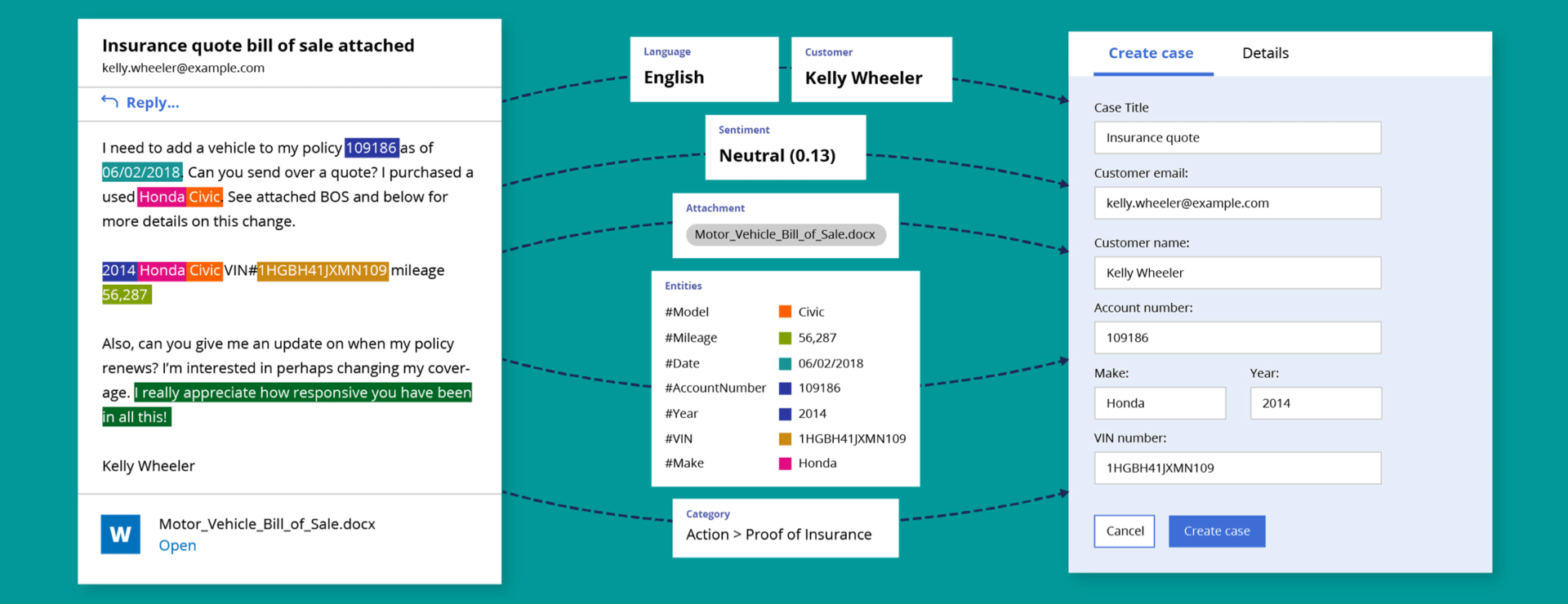
Training
To obtain accurate predictions from the machine learning models in Pega, effective preparation of the training data is essential. For the text extraction models, CSV, XLS, or XLSX files are used, which must meet specific requirements.
The text extraction model requires a file with two columns: “Content” and “Type.” The ‘Content’ column contains the email data, while the “Type” column specifies whether the data is for training or testing. The data in the “Content” column is formatted according to a specific pattern, with entities defined by markers such as <START:...> and <END>. These entities, such as “Change_bank_details,” are later mapped to variables in Pega and enable the automatic filling of fields.
Share





